Infrastructure management adds an additional layer of complexity to the modern software development workflow. Keeping servers up and running, taking care of security updates, and scaling resources takes up valuable time from DevOps teams. With serverless computing, all infrastructure operations are handled by the service provider. As such, serverless allows development teams to focus on writing code rather than spending too much time on infrastructure management.
This article explains what serverless computing is and how it compares to different cloud deployment models. We’ll also explore the pros and cons of serverless and talk about some common use cases.
What is Serverless Computing?
Serverless computing is a method of deploying and running code in the cloud without dealing with server provisioning and infrastructure management. Despite its name, serverless still relies on cloud or physical servers for code execution. However, developers are not concerned with the underlying infrastructure. This is left to the serverless provider which dynamically allocates the necessary compute resources and manages them on behalf of the user.
For developers, this means zero time spent on server administration, maintenance, resource scaling, or capacity planning. They simply upload their code and let the provider run the server-side logic based on different events or requests. In contrast to familiar cloud billing models, serverless services are charged based on the number of times the code is executed or when a certain event is triggered.
How Serverless Computing Works?
In a serverless environment, code is triggered by events and executed as a function. This is why serverless is often associated with “Functions-as-a-Service” or FaaS, which is a similar concept. FaaS is an event-driven cloud model that handles the server-side logic for code execution without any intervention from the user. These events can be anything from a simple HTTP request, API call, to a database query or file upload.
Functions are executed in stateless containers. This means that compute resources for running a function are provisioned only when invoked. No data is persisted in RAM or written to the disk. Once the request has been fulfilled, the state of the app is reset and there is no memory of the transaction. Making a new request calls for the resources to be provisioned from scratch and the code is executed without any reference to the previous invocation.
To accommodate this stateless state, applications need to be architectured as functions that can run in stateless containers. This is usually achieved through microservices. Large monolith apps are broken down into smaller segments and interconnected through an API. Monolith apps can still run as single functions, but this is not a common practice. Having in mind that a new compute container is provisioned on every request, large functions will negatively impact execution speed and duration.
FaaS functions don’t run infinitely. They are terminated after a certain amount of time upon being called. In most cases, functions timeout after about five minutes. This means that apps that run long-duration tasks need to be redesigned to account for termination limits.
Provisioning and initializing containers for function execution also takes time. This is usually measured in milliseconds. However, complex functions may take several seconds to initialize, thus causing greater latency.
There are two common methods for initializing a function — warm start and cold start. A warn start reuses resources from a previous event, whereas a cold start deploys a new container. The time it takes to initialize and execute a function will depend on the amount of code, the programming language, the number of libraries the script uses, as well as many other factors. In terms of latency, a cold start takes more time to start a function.

How Serverless Computing Compares to BaaS, PaaS, and IaaS?
As with any software trend, there is no official definition that describes what serverless is and what it is not. That’s why serverless computing is often confused with other cloud services and deployment models. The concept of serverless computing revolves around two similar areas:
Backend-as-a-Service — BaaS enables developers to focus on writing frontend interfaces while offloading all backend operations to a service provider. These behind-the-scenes tasks usually involve ready-to-go user authentication, storage, database management, and hosting services. Also, developers don’t have to manage servers running their backend, enabling faster app deployments.
Functions-as-a-Service — This serverless cloud service model does away with infrastructure management. The service provider is tasked with deploying compute resources on-demand to execute the users’ code. This happens whenever an event or request is triggered. Serverless functions run in stateless containers, meaning compute resources are deployed only when the function is invoked.
The main point of confusion is between Backend-as-a-Service and Platform-as-a-Service (PaaS). The former is a technique of serverless computing, while the latter is a cloud deployment model. Even though they share some basic characteristics, PaaS is not aligned with the requirements of serverless.
Platform-as-a-Service — With PaaS, users rent the hardware and software solutions necessary for development workloads from a service provider for a subscription fee. It allows developers to spend more time coding without worrying about infrastructure management. On the other hand, BaaS offers additional features such as out-of-the-box user authentication, managed databases, email notifications, and the like. BaaS also allows developers to focus solely on building the frontend while integrating various backend services on demand.
Infrastructure-as-a-Service — IaaS refers to a self-service cloud solution where the provider hosts the infrastructure on behalf of the user. All server provisioning and management operations including software installation are handled by the user. Some IaaS providers also offer serverless solutions but as distinctly different products.
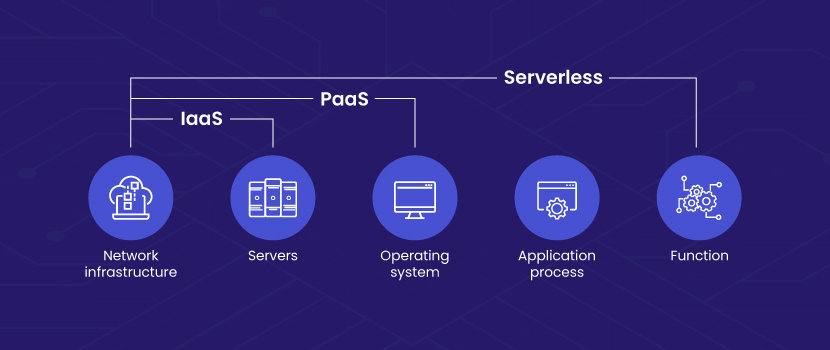
Check out this article to learn about the differences between IaaS, PaaS, and SaaS.
Common Serverless Computing Use Cases
As mentioned earlier, serverless is not for everyone. But if your needs are aligned with some of these use cases, you might benefit from serverless.
Building APIs
With no servers to manage, building highly scalable and responsive APIs is one of the more popular use cases for serverless. The auto-scaling feature of serverless ensures that APIs will always be available even under heavy traffic. In addition to this, the user is not charged for idle resources when there are no calls to the API.
Websites and Applications
Deploying websites and web-based apps on a serverless platform does not require any prior infrastructure setup. This significantly cuts the time it takes to launch a fully functional web app. The auto-scaling feature also plays a significant role here because the user does not need to worry about provisioning more servers to support increases in demand. As a result, it’s much easier to maintain 100% uptime.
Multi-Language Applications
With serverless, a single app can be written in various languages. Serverless allows developers to break up a monolith app into smaller parts and run them as microservices. Those microservices then communicate with each other via an API. Each segment of an app can be written using a different programming language.
CI/CD Pipelines
Automation is key to running successful development, testing, and integration pipelines. Serverless allows developers to automatically test code and fix bugs faster. Since serverless is event-based, users can set events to trigger automated tests without any manual intervention.
Learn how to build your own DevOps pipeline.
What Are the Advantages of Serverless Computing?
Compared to traditional server-oriented cloud computing, serverless computing abstracts away infrastructure operations. Everything works out-of-the-box which in turn ensures faster code releases and automated scalability at a lower price point.
These are the three most common benefits of serverless:
Auto-Scaling
The serverless provider scales infrastructure resources based on demand. Scaling operations are performed dynamically and automatically without any intervention from developers.
Faster Time to Market
Without needing to provision complex server clusters, developers can focus more on achieving higher release velocity. This speeds up the time it takes to release code to production or implement incremental code changes, resulting in faster delivery of apps to customers.
Optimized Costs
Since everything is provisioned on-demand, organizations never have to pay for unused storage space, compute time, or networking. Consumption of serverless services is typically measured in milliseconds and billed accordingly.
What Are the Drawbacks of Serverless Computing?
As with any software solution, serverless too comes with some downsides. But depending on the app you’re building, you might not be so concerned with some of these drawbacks of serverless.
Latency
When executing a function, serverless providers automatically deploy the necessary resources on every invocation. Depending on the size of the workload, containers are typically provisioned in milliseconds but can even take several seconds. Latency can be reduced through “warn starts” which reuse instances from a previous execution.
Execution Duration
The execution time of a serverless function is limited and gets aborted after a certain period. This is usually around five minutes after invocation but varies across providers. Execution limits are a major drawback for apps that initiate long-duration processes. Mitigating this issue is possible by segmenting the code into smaller chunks and running them as microservices.
Vendor Lock-In
Providers usually use proprietary technologies to enable their serverless services. This may cause issues for users who want to migrate their workloads to another platform. When moving to another provider, changes to the code and the app’s architecture are inevitable.
Security
Users have little control over the instance configuration running their code. This is hidden from the user and falls in the realm of the service provider. As such, security operations also fall in the hands of the provider. The user is helpless if an attack occurs, relying solely on the provider to mitigate the damage and recover the system. Applications that have multiple entry points in a serverless environment are more prone to vulnerabilities due to an increased attack surface.
What’s the Future for Serverless Computing?
Serverless computing is still a relatively new technology. Its future depends on the ability of service providers to resolve some of the drawbacks listed above — most importantly, cold starts. Providers need to cut the time it takes to execute a function after it’s been in the idle state for a while. Solving this issue will decrease latency and ensure a seamless user experience.
Serverless currently relies on stateless containers for function execution. The future of serverless is moving toward enabling stateful apps to leverage the benefits of serverless. This will allow developers to build stateful apps without worrying about backend data management.
In terms of DevOps, serverless will lead to the expansion of NoOps. This trend will lead to serverless providers handling all infrastructure operations on behalf of the customer. In such a setting, there’s no need for companies to have in-house operations teams.
In the coming years, Kubernetes is expected to become the foundation of serverless. With support for networking, agile auto-scaling, and multi-cloud deployments, Kubernetes portability enhances serverless computing in more ways than one. Running certain classes of apps in serverless is impractical as service providers sometimes limit their behavior. With Kubernetes, developers will be able to overcome those limitations and build serverless platforms based on their specific needs.
Conclusion
Even though the name suggests the absence of servers, serverless computing still relies on cloud or physical servers. It is a computing model that eliminates infrastructure operations, allowing developers to focus on writing and deploying apps. The serverless model revolves around two key areas: Backend-as-a-Service and Functions-as-a-Service.
The former provides users with a ready-to-go backend architecture, while the latter enables running apps in stateless containers. These containers are provisioned automatically based on events or triggers. As such, serverless is not a silver bullet solution for all current development problems. It’s mostly geared toward non-monolithic apps that employ a microservices-based architecture.
Try Bare Metal Cloud for as low as $0.10/hour! Create an account and spin up your first server in minutes. Get started here.




